
Out-of-Order Execution and Meltdown
UCL Course COMP0133: Distributed Systems and Security LEC-20
Consequence of Meltdown
-
Meltdown vulnerability is in CPU hardware
-
A malicious program can read kernel memory
-
The malicious program can read memory of all processes because kernel memory generally maps all physical memory
-
The malicious programs within paravirtualized virtual machines and Docker containers
can read memory of other VMs/containers
Background: CPU Cache and Memory Hierarchy
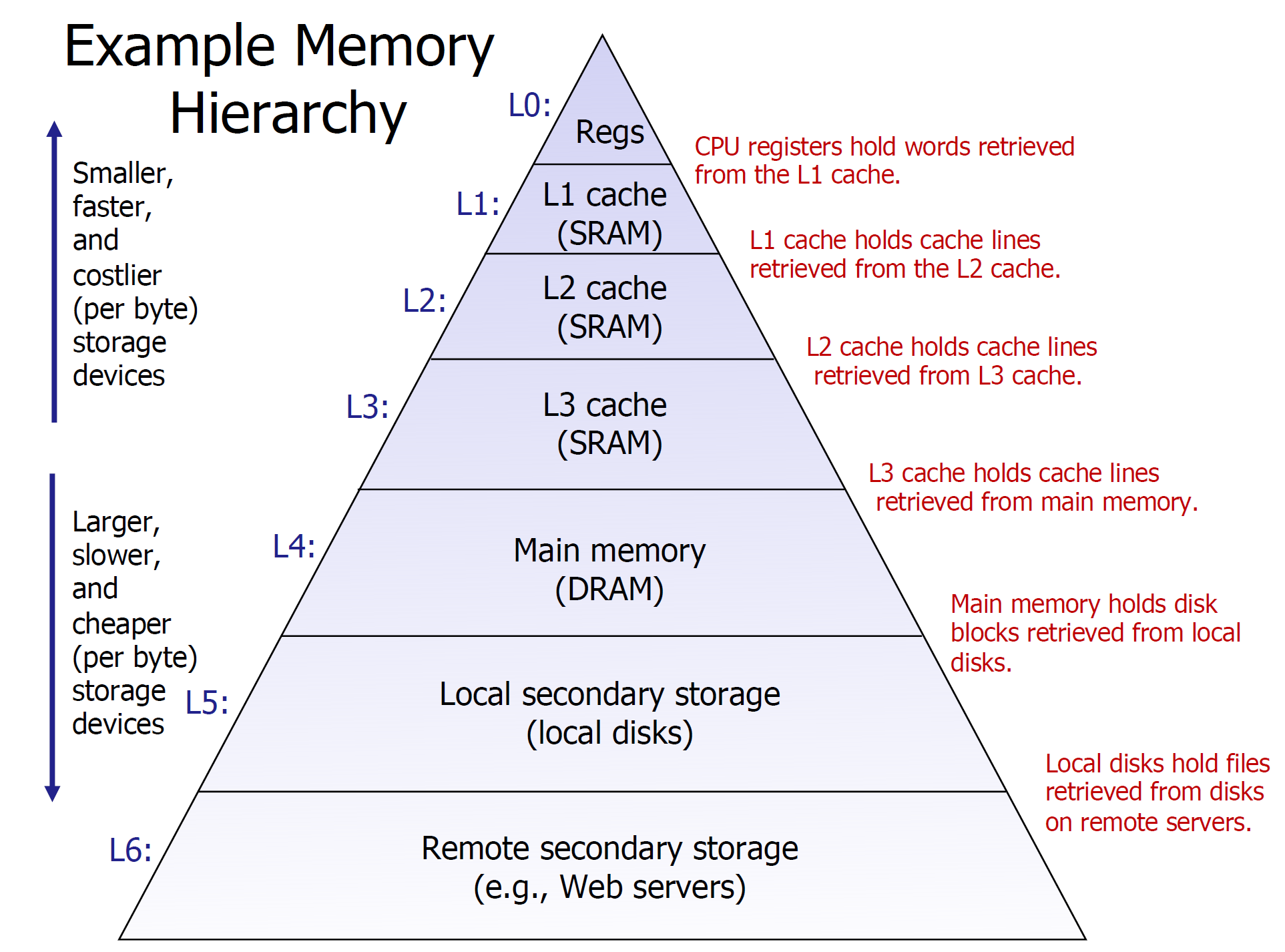
Higher layer memory will be a subset of lower layer memory
Load data block from higher layer to lower layer
-
if miss, find the next lower layer (DRAM) and store the block into higher layer (CPU Cache) —– SLOW
-
if hit, directly load the block in the higher layer (CPU Cache) —– FAST
Background: Virtual Memory for Protection and Isolation
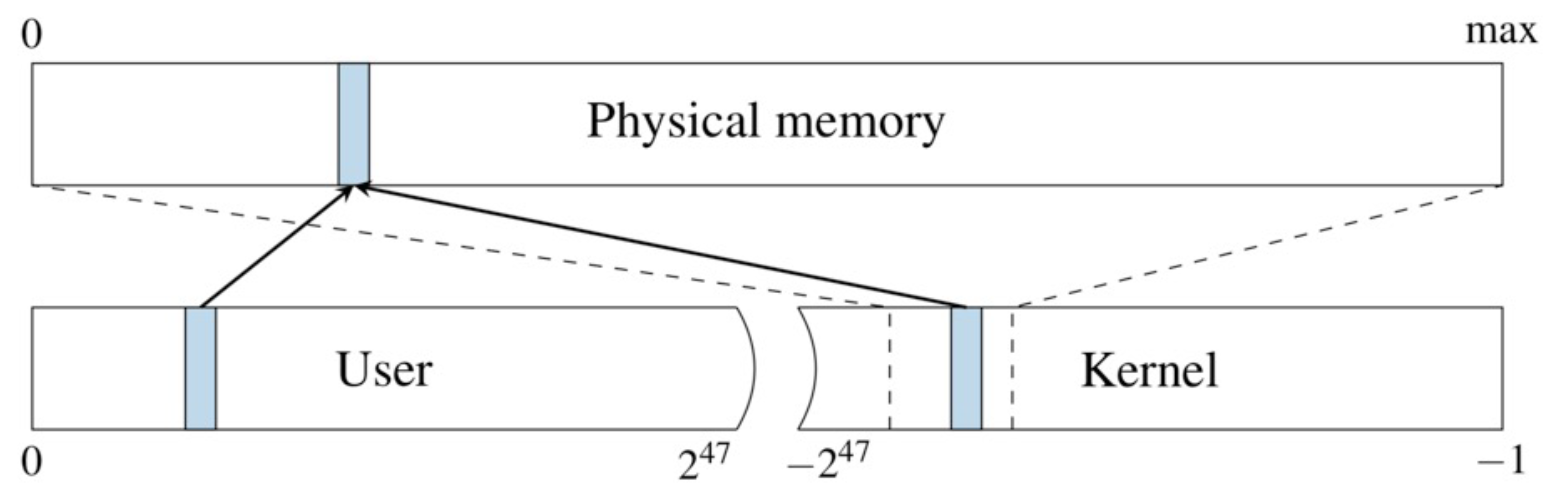
Every Linux process has user memory region and kernel memory region
in its virtual address space (can access user memory only)
The entire physical memory (all process memory) will be mapped into
a contiguous memory space in the kernel memory region
Reason for Performance
-
avoid changing page tables and flushing TLB on switches between user code and kernel code when two processes communicate
-
convenient and fast for kernel always to map all physical memory (able to access memory of processes)
Each process will be represented by the same virtual memory address range (each virtual memory is isolated)
Background: CPU Pipelines
Idea
-
Divide process into independent stages
-
Move objects through stages in sequence
-
At any given time, multiple objects being processed
CPU Pipelines
Divide instruction execution into pipeline
-
short and sequentially arranged stages
-
stages operate concurrently as pipeline fills with instructions
-
instructions advance to next stage each clock cycle
-
one instruction will be completed by CPU per clock cycle (oversimplified)
Shorter pipeline stages \( \implies\) Deeper pipelines \( \implies\) Higher clock rates \( \implies\) Faster instruction completion rate
Duplicate pipeline can be used to execute even more instructions concurrently
Problem
-
Any instruction requires several clock cycle to finish
-
Pipeline Stall happens when subsequent instruction needs result from the prior one
which means the subsequent instruction needs to wait (be freezed) for the prior one to finish
Background: Out-of-Order Execution
Goal
Mitigate the performance problem caused by Pipeline Stall to keep CPU busy
Idea
If instructions wait for other unfinished inputs (CPU functional units idle,)
fetch instructions from later (not need to wait extra input) in program
and if the required inputs are ready, execute them now
Problem
CPU hardware may execute instructions in order other than given in program
Solution
CPU hardware ensures that
-
instructions will only be retired in program order
retire instructions means to write back externally visible results (e.g., in register)
-
later instructions in program order executed “early” are squashed if instruction causes a hardware exception
such that results are still not written back externally visible results (e.g., in register)
Background: Flush + Reload
Goal
Determine whether the process has accessed target address in the memory of this process during some period
Steps
-
Flush part of data cache that holds the target address using
clflushinstruction (cache not been cached any more) -
Wait to allow access to target address to occur
-
Time the latency of reading from target address
-
Short Latency: cache hit, so program accessed target address during wait
-
Long Latency: cache miss, so program not accessed target address during wait
-
Meltdown
Goal
In a user-level and non-root process, read data from virtual memory of another process
Steps
-
Flush the CPU data cache for a range of valid process memory addresses —– Flush
-
Tell OS not to kill the process when segmentation fault occurs
-
Read from target kernel virtual memory address
Note: this will cause segmentation fault once CPU detects invalid address
-
Read from valid in-process memory address derived from value read from kernel virtual memory address
Note: this will be executed because of out-of-order execution
-
Time reads from all addresses prior step might have read from —– Reload
one that completes more quickly than all others reveals kernel memory value
Implementation: Byte-at-a-Time
Assembly
xorq %rax, %rax xor rax, rax
retry: retry:
movb (%rcx), %al mov al, BYTE [rcx]
shl %rax, $0xc shl rax, 0xc
jz retry jz retry
movq (%rbx, %rax, 1), %rbx mov rbx, QWORD [rbx + rax]
Register rcx holds target kernel memory address where attackers want to read one byte from
Register rbx holds base address of 256 pages in user space (the size of each page is 4 KB)
Explanation
Step 1 (allocate 256 pages in process user-level memory and flush cache) and Step 2 (not kill process) have been completed
-
Line 1:
xorq %rax, %raxset value in registerraxto 0 -
Line 2:
retry:place theretrylabel -
Line 3:
movb (%rcx), %alread one byte from target address stored in registerrcxNote: this will eventually cause segmentation fault, but CPU still loads the byte into
alinitially -
Line 4:
shl %rax, $0xcmultiple the byte read from kernel by 4096 by left shifting 0xc (a page size)Note: this will be executed before segmentation fault caused by the prior instruction because of out-of-order execution
Reason:
One page apart for every possible byte from kernel memory and CPU will not prefetch across page boundaries
where prefetching will read more bytes than requested automatically for performance
which will lead to messing up the determination of which byte read from kernel
-
Line 5:
jz retryretry when the byte read from kernel (currently stored in registerrax) is still 0Note: this will happen occasionally because CPU not propagate kernel read result
and the loop will terminate either when non-zero value read or when segmentation fault is delivered to application
-
Line 6:
movq (%rbx, %rax, 1), %rbxstore value in addressrbx + raxinto registerrbxThis address
rbx + raxis read to cache the corresponding cache linesuch that it will be loaded into the data cache of the requesting core
and will eventually affect the cache state based on the value of byte read from kernel (currently stored in register
rax)
Step 5 read from start of all 256 pages and time the latency for each read
which will find a much faster (lower latency) read for page \( i \) than all other pages
that indicate value of byte read from target kernel memory is \( i \)
Because core code may see zero erroneously, cache hit in page 0 NOT mean 0 read from kernel memory
Instead, absence of cache hit on any other page will mean 0 truly read
Optimization: Bit-at-a-Time
Motivation
Byte-at-a-Time need to scan 256 pages for Flush + Reload to find one byte of kernel memory (very expensive)
Modification
Add instructions to “core” Meltdown routine to mask, and
shift single bit of the byte read from kernel memory (make versions for all 8 bits — 1 byte)
such that currently need 1 page for Flush + Reload to find one bit of kernel memory (8 pages for one byte)
since only page 1 is needed to scan: if fast, receive 1 bit; if slow, receive 0 bit
Reasons for Success
Reading from kernel virtual address (no permission for user level to read) will cause process to be halted, but
-
CPU needs a long time to detect violation because of pipeline such that
the out-of-order execution will keep executing more program
before CPU realizes earlier instruction accessed forbidden memory
-
Process can catch segmentation fault rather being killed by OS —– Step 2
Out-of-order execution results that should not be computed
will be squashed by CPU through restoring registers to their old values, but
-
cache occupancy for allowed memory accesses will survive after a squash
e.g., reading from valid in-process memory address derived from value read from kernel virtual memory address —– Step 4
Mitigation
Software
Kernel Page Table Isolation (KPTI) will
change kernel to not map kernel pages into user processes page tables
(apart from a few pages needed for kernel entry points)
such that when process makes system call
OS must first change active page table to map kernel memory, and reverse this before resuming user process
which leads to cost heavily workload-dependent (up to 30%+ performance reduction)
Hardware
Newer Hardware (e.g., Intel) cause
memory reads to check whether target address legal (and if not, deliver hardware exception)
before out-of-order exectution of later instructions can modify cache
However,
they are still vulnerable to new “Fallout” Meltdown-like attacks
which targets CPU store buffer hardware and leaks kernel writes to user-level code
such that
-
KPTI is still needed
-
CPU microcode should be updated
-
Repurposed
VERWinstruction on context switch to flush store buffer explicitly
Lesson
-
Modern CPU architectures are rife with side channels:
现代 CPU 架构充斥着旁通道
state held by the CPU (e.g., caches) that can leak information in subtle ways (e.g., through timing)
CPU 持有的状态(例如,缓存)可以以微妙的方式(例如,通过时序)泄漏信息
-
CPU vendors appear to have been largely oblivious to privacy risks
caused by performance-improving optimizations since the mid 1990s自 1990 年代中期以来,CPU 供应商似乎在很大程度上忽略了由性能改进优化引起的隐私风险
(e.g., out-of-order execution, speculative execution, etc.)
-
Meltdown (and Spectre) unlikely to be the last CPU privacy vulnerabilities of this sort
Meltdown(和 Spectre)不太可能是此类最后一个 CPU 隐私漏洞
(e.g., Foreshadow, L1 Terminal Fault, Fallout, etc.)
-
Those with strongest need for privacy
对隐私有最强烈需求的人
should be vigilant about risks of running on shared hardware alongside users and/or code they don’t trust
应该警惕与他们不信任的用户和/或代码一起在共享硬件上运行的风险
-
Considerable research effort in architecture community today
on mitigating microarchitectural side channels without killing CPU performance
当今架构社区在不影响 CPU 性能的情况下减轻微架构侧通道的大量研究工作