
Two-Phase Commit
UCL Course COMP0133: Distributed Systems and Security LEC-06
NFS and Ivy Review
NFS
-
Share one filesystem among clients
-
Explicit communication (RPC)
-
Caching
-
Weak Consistency
Ivy
-
Share virtual memory among CPUs
-
Implicit communication
-
Read-only sharing
-
Strong Consistency
Failure and Atomicity
When two servers must take an action in a distributed system,
-
when action succeeds, both should do the action in correct order
-
when action fails, neither should do the action (avoid one side to act)
Two Kinds of Atomicity
Serializability
Outside observer sees series of operations requested by users
that each complete atomically in some complete order
Solution: Locking and Unlocking
Recoverability
Each operation executes completely or not at all (“all-or-nothing semantics”)
such that no partial results exist
Solution: Two-Phase Commit
Components
-
Client
-
Transaction Coordinator (TC)
-
Server A
-
Server B
Strawman Atomic Commit (Wrong)
Process
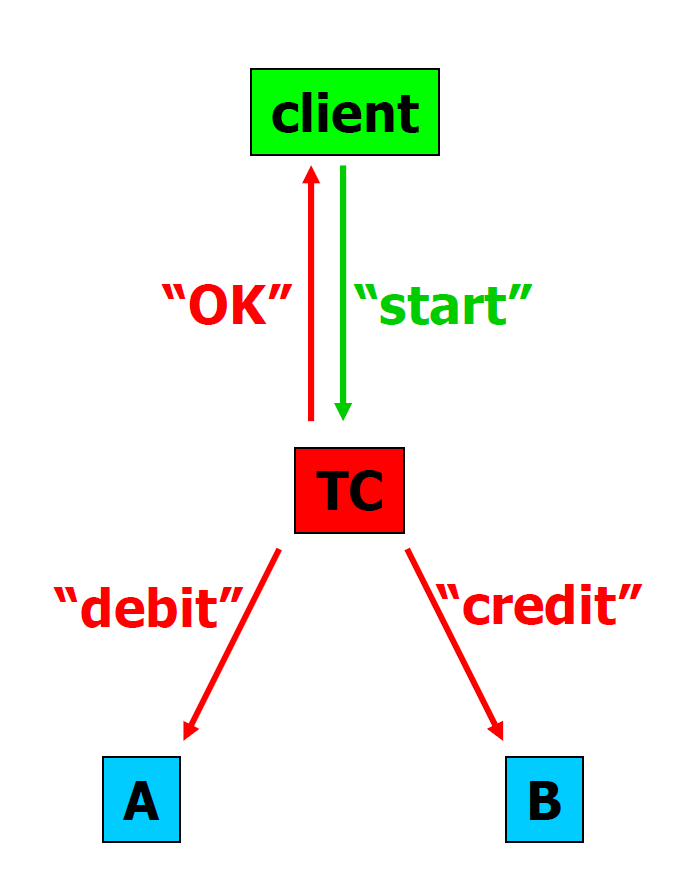
-
Client —start—> TC
-
TC —debit—> Server A
-
TC —credit—> Server B
-
TC —ok—> Client
Disagreement when Failure
Server A not commit but Server B commit, e.g.,
-
Not enough money in account of Bank A (Transfer Scenario)
-
Server A crash or Network to A down
Server A commit but Server B not commit, e.g.,
-
No existed account of Bank B (Transfer Scenario)
-
Server B crash or Network to B down
-
TC crash between sending to A and sending to B
Properties of Atomic Commit
Safety
-
If one commit, no one abort
-
If one abort, no one commit
Liveness
-
If transaction succeed, A and B commit, finally commit
-
If transaction fail, the system should come to some conclusion ASAP
Commonly, safety should be more important than liveness
Correct Atomic Commit (Safety)
Process
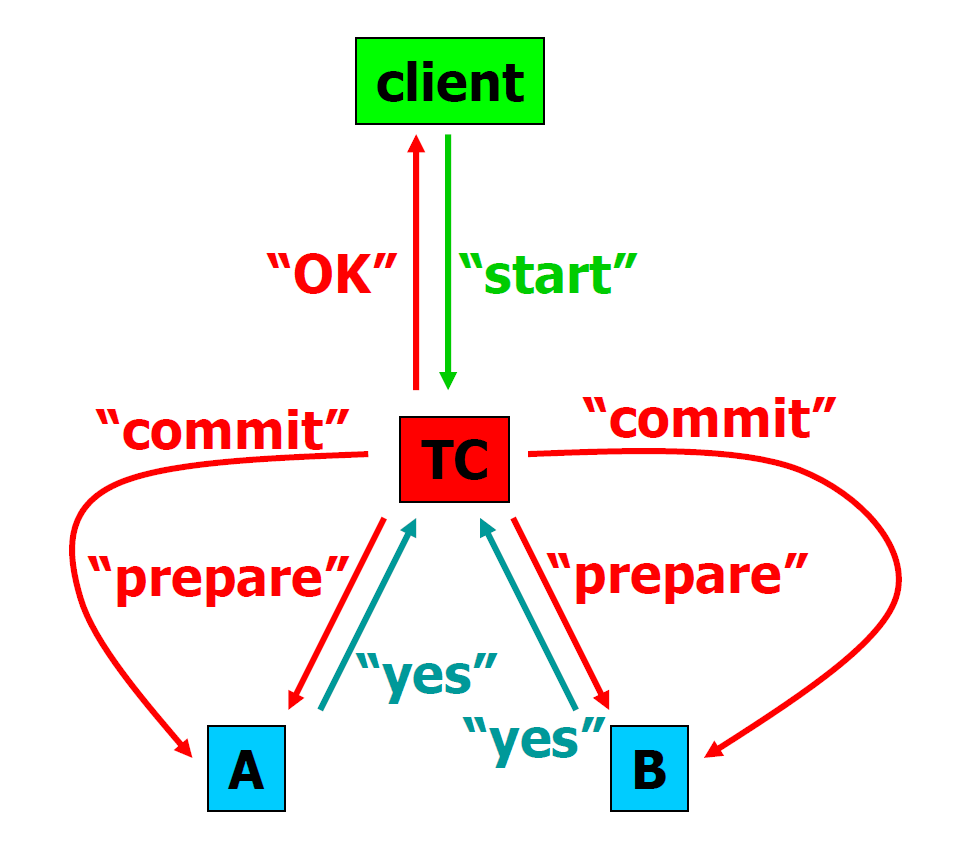
Phase 1: Prepare
-
Client —start—> TC
-
TC —prepare—> Server A
-
TC —prepare—> Server B
-
Server A —Yes/No—> TC
-
Server B —Yes/No—> TC
Phase 2-1: Commit
If both Server A and B send “Yes” to TC, come to commit phase
-
TC —commit—> Server A
-
TC —commit—> Server B
-
TC —ok—> Client
Phase 2-2: Abort
If one of Server A and B send “No” to TC, come to abort phase
-
TC —abort—> Server A
-
TC —abort—> Server B
Safety (Yes)
TC is centralized such that it can know decisions of both Server A and B (enforced agreement)
Liveness (No)
Timeout
-
TC wait for “Yes/No” from Server A and B
TC is conservative (Safety »> Liveness)
such that it will abort when message is lost or come late (set a time for timeout) -
Server A and B wait for “Commit/Abort” from TC
Assume Server B is waiting (Server A is the same)
when Server B vote “No”, Server B can simply think TC will abort
when Server B vote “Yes”, Server B should wait forever for TC
(cannot decide to abort or commit since Server A can vote “Yes” or “No”)Termination Protocol as a Mitigation when Server B Vote “Yes”
Server B will sent status request to Server A what Server A vote for
-
No reply from Server A: Server B wait forever for TC
-
Server A receive “Commit/Abort” from TC: Server B make the same decision
-
Server A has not voted “Yes” or “No”: Both Server A and B abort (TC cannot commit before receiving from A)
-
Server A vote “No”: Both Server A and B abort
-
Server A vote “Yes”: Server B wait forever for TC (TC can commit but can also abort when TC timeout)
-
Crash-and-Reboot
The “commit” decision should not be back after it has been decided
-
TC crash after deciding and sending “Commit” to Server A and B
-
Server A and B crash after deciding and sending “Yes” to TC
Persistent State as a Solution when Crash and Reboot
such that all nodes should know their state before crash (using non-volatile memory)
Order: Write then Send
-
When TC find that no “Commit” is on disk after reboot, it will abort
-
When TC find that “Commit” is on disk after reboot, it will commit
-
When Server A and B find that no “Yes” is on disk after reboot, it will abort
-
When Server A and B find that “Yes” is on disk after reboot, it will use Terminiation Protocol
Conclusion
Safety
-
All hosts that decide reach same decision because of the centralized TC
-
No “Commit” from TC unless every server vote “Yes”
Liveness
-
If no failures and every server vote “Yes”, then commit
-
if failures, then repair, wait long enough, eventually some decision
Theorem
No distributed asynchronous protocol can correctly agree (provide both safety and liveness)
in presence of crash-failures (i.e., if failures not repaired)