
Network File System
UCL Course COMP0133: Distributed Systems and Security LEC-03
Design of Network File System (NFS)
Motivation
-
Data sharing
many users read and/or write same files (e.g., code repository)
but run on separate machines
-
Manageability
ease of backing up one server (reliability) than all employee’s devices
backup is necessary
-
Disks may be expensive
True when NFS built - no longer true
-
Displays may be expensive
True when NFS built - no longer true
Goal
-
Work with exisitng unmodified applications
Same semantics ad local UNIX filesystem
-
Easily deployed
Easy to add to existing UNIX filesystem
-
Compatible with non-UNIX OS
Wire protocol cannot be too UNIX-specific
-
Efficient “enough”
Need not offer the same performance as local UNIX filesystem
New Jersey Design Approach
Interaction
Applications exactly the same syscalls to the kernel,
the kernel does not access the local file system
but generates a remote procedure call (RPC) to the server over the LAN
the server will do what the client requests, and then returns the result
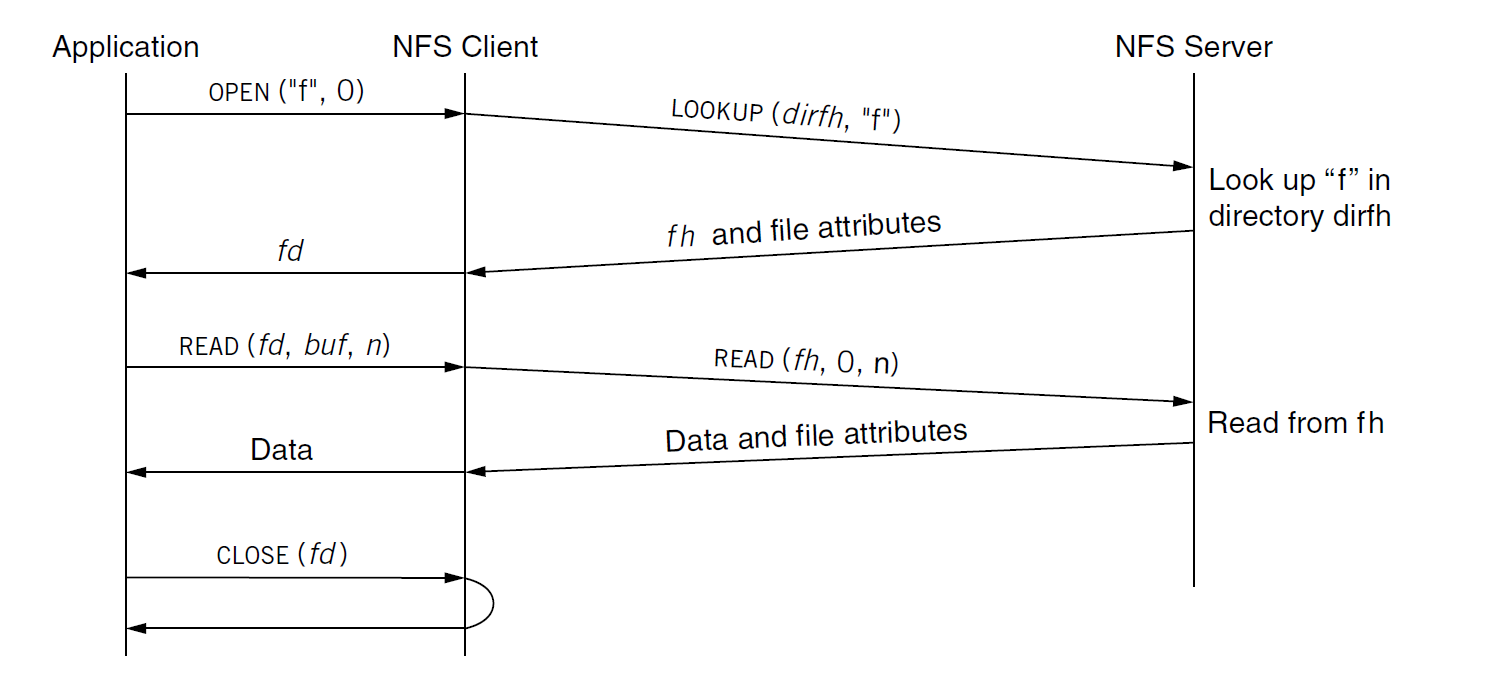
Example: Reading a File
fd = open("f", 0);
read(fd, buf, 8192);
close(fd);
-
The system call,
OPEN("f", 0), in the application level in the client side -
The client kernel invokes a RPC,
LOOKUP(dirfh, "f"), from the client to the serverdirfh: the working directory that server should look up (referred to a file handle)"f": the string file name -
The server looks up
"f"in directorydirfhby invoking look up function -
The server replies a file handle
fhfor"f"and related file attributes (e.g., permission, meta data …) -
The system call,
READ(fd, buf, n), in the application level in the client side -
The client kernel invokes a RPC,
READ(fh, 0, n), from the client to the server0means the begnning of the file (Note: client-sideREADsyscall does not implicit the offset) -
The server reads data from
fhby invoking read function -
The server replies data and related file attributes
Because the NFS is stateless (for servers working well when they crash and reboot),
the server does not care or track which files are open on which clients,
therefore, there is no need a RPC for the close() system call (and no offset in READ RPC)
File Handle
A 32-byte object identification on remote server
(opaque to client \( \implies \) only server can interpret)
must be contained in all NFS RPCs
which contains
-
filesystem ID (namespace on disk)
-
i-number (physical block ID on disk)
-
generation number
Motivation of i-number (not filename)

Between Application 1 (Client 1) OPEN and READ the target file,
Application 2 (Client 2) renames the pathname (also filename)
UNIX local file system semantics
Application 1 reads dir2/f
(not impact local file system - the kernel has a centralized global control (stateful)
which has a table of which files are open, and already caches the i-number of that filename)
NFS semantics if server reuses i-node
Client 1 reads dir1/f
Solution
i-number refers a physical block on disk (actual object)
Motivation of Generation Number
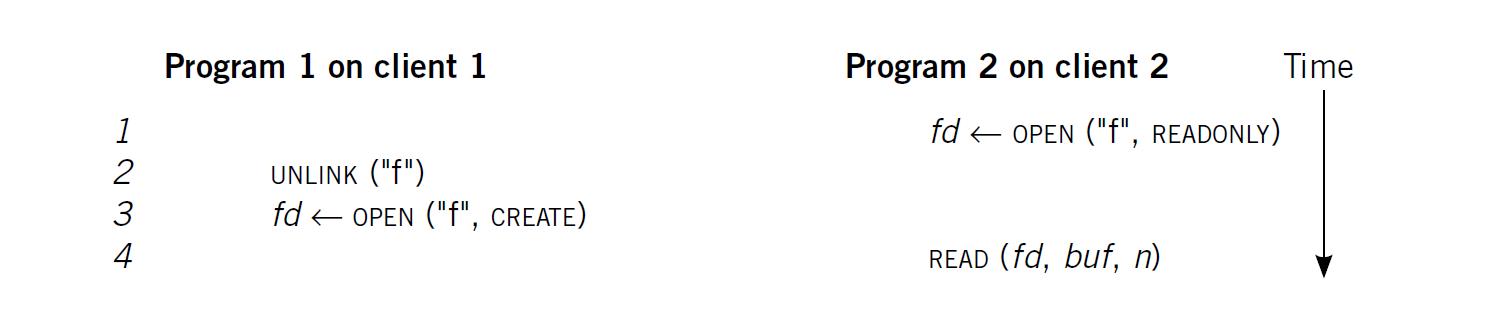
Application 1 (Client 1) opens file + Application 2 (Client 2) opens the same file +
Application 1 (Client 1) deletes the file and creates a new one
UNIX local file system semantics
Application 2 will see the old file until it closes the file (for least confusing)
Even though Application 2 writes after deleting, the file will vanish after closing it
(not impact local file system - the kernel has a centralized global control - stateful
which has a table of which files are open, and does not put files that are using into the free list)
NFS semantics if server reuses i-node
Reusing i-node means using the same i-number for new files
such that RPCs from Client 2 will refer to the i-number of new file
then Client 2 sees new file
Solution
Each time the server frees i-node, its generation number will be increased
such that Client 2 now uses the old file handle \( \implies \) Client 2 gets stale file handle error
which is the different semantic from local file system
Process of Obtaining File Handle
When the client first starts to use NFS, there is a seperate step for bootstrapping
The RPC, called MOUNT , will return the first file handle for the root directory of the file system
This RPC should use a path name path (if the path of root directory is changed, nothing would work)
Before READ, client obtains file handle using LOOKUP (existed file) or CREATE (not existed file)
The client will store the returned file handle in vnode (where the file descriptor refers to vnode)
The vnode Interface
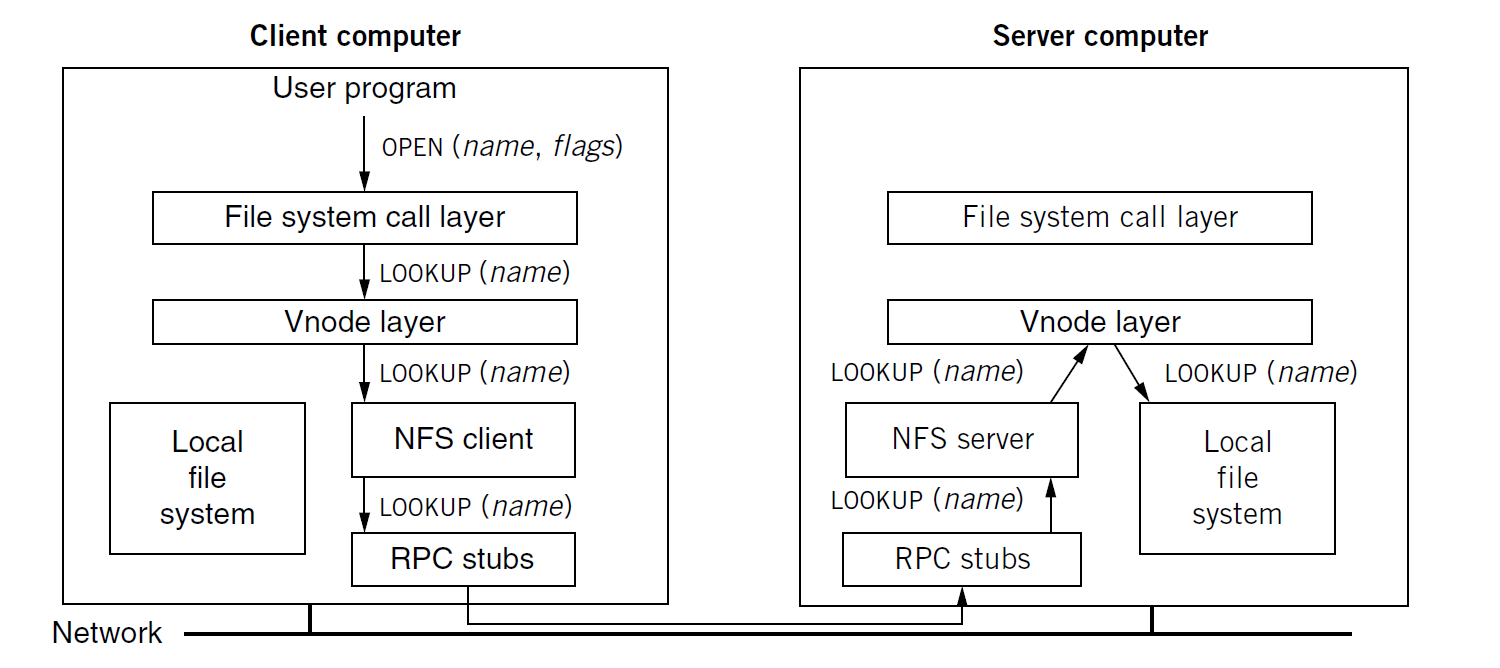
A new layer, called vnode interface, is added between file system calls and disk controller in the kernel
to determine the file system calls into local file system or NFS client (with same function names and parameters)
However,
local file system and NFS client have different implementation for file system calls (not 1-to-1 mapping)
because the UNIX semantics defined files by a mix of filename and i-number on disk
That’s the reason that not send file system call over network directly
Purpose of vnode: remember file handles for future uses
Example: Creating a File
The client-side syscalls
fd = creat("d/f", 0666);
write(fd, "foo", 3);
close(fd);
The RPC sent by client
newfh = LOOKUP(fh, "d"); // get the file handle of the directory "d"
filefh = CREATE(newfh, "f", 0666); // get the file handle of the created file "f"
WRITE(filefh, 0, 3, "foo"); // write data into the file "f"
Problems in Network File Systems (NFS)
Servers Crash and Reboot
Note: The file handle in client side still works (disk address of i-node)
Q: What if the server crashes after the client sends an RPC?
Answer:
Before the server turns back, the client will not get reply and will keep retrying
Q: What if the server crashes after replying a WRITE RPC before writing?
Answer:
-
The data of the client should be safe on disk
-
The i-node with new block number and new length of bytes should be safe on disk
-
The block should be indirectly safe on disk
Three objects within different regions on disk all need writes and seeks for one WRITE RPC
Synchronous WRITE:
The server is allowed to reply to the client only after meeting all three requirements
There will have a huge performance reduction compared with the physical disk throughput
Caches in Clients Change
For performance, clients and servers need to cache data
-
Servers cache disk blocks
-
Clients cache file content blocks, file attributes, name-to-file-handle mappings, directory contents
Q: What if Client A caches data but Client B changes them on server?
The Multi-Client Consistency Problem
If client asks server whether files have changed on every read()
Not sufficient to make each read() see latest write() (one possible reason: network delays)
alongside a huge reduction on performance
Solution: Close-to-Open Consistency
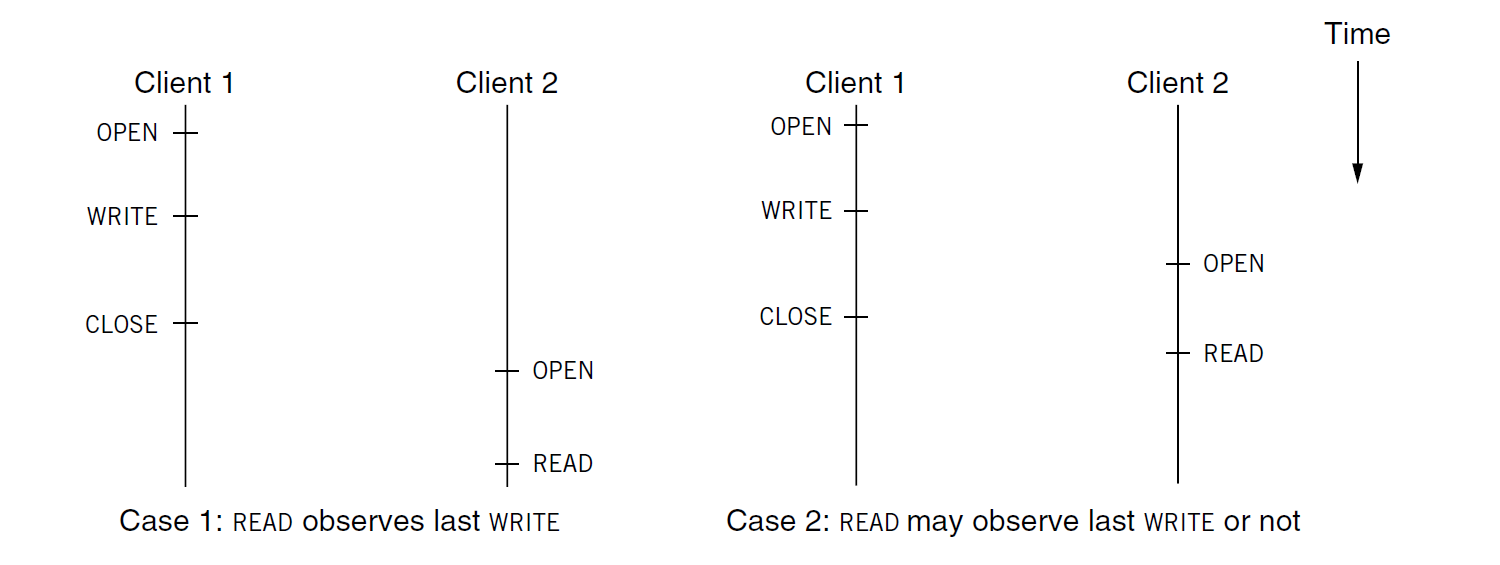
In case 1
If Client 1 open()s, writes()s a file and then close()s the file
Then, Client 2 opens()s the file and then read()s the file
The read() of Client 2 should observe the write() of Client 1
In case 2
If Client 1 open()s and writes()s a file
Client 2 opens()s the file and then read()s the file before Client 1 close()s the file
The read() of Client 2 may observe the write() of Client 1 or not (both correct in Close-to-Open Consistency)
Benefits:
The client only needs to contact the server during open() and close() (not every read() and write())
Close-to-Open Implementation in FreeBSD UNIX Client
-
client keeps file mtime (last modification time) and size for each cached file block
tracking these metadata can determine the file is changed or not
-
close() starts WRITEs for all file’s dirty blocks (the modified blocks)
-
close() waits for all of server’s replies to those WRITEs (data safe on disk)
-
open() always sends GETATTR to check file’s mtime and size, caches file attributes
-
read() uses cached blocks only if mtime and size have not changed
-
client checks cached directory contents (the list of files) with GETATTR and ctime (last change time)
Hoever, name-to-file-handle mappings are not always checked for consistency on each LOOKUP for performance
-
if file deleted, may get stale file handle error from server
-
if file renamed and new file created with the same name, may get wrong file content
Limitations of NFS
Security
-
Not prevent unauthorized users from issuing RPCs to a NFS server
might the authentication is IP/MAC-address-based but very weak
-
Not prevent unauthorized users from forging NFS replies to a NFS client
Scalability
Consider the number of clients can share one server
-
Every WRITE should go through to server (how many writes are allowed)
-
Some writes to unshared files will be deleted soon after creation (e.g., scratch space for temporary data)
Performance
Run NFS over a large and complex network: latency? packet loss? bottlenecks?